import matplotlib
if not hasattr(matplotlib.RcParams, "_get"):
matplotlib.RcParams._get = dict.get
(Optional) DDIM (Denoising Diffusion Implicit Models): From the DDPM Perspective#
This notebook assumes you already understand DDPMs well, including:
the forward diffusion process
the closed-form marginal \(q(x_t \mid x_0)\)
the posterior \(q(x_{t-1}\mid x_t, x_0)\)
the learned reverse model \(p_\theta(x_{t-1}\mid x_t)\)
ELBO training
\(\epsilon\)-prediction, \(x_0\)-prediction, and \(v\)-prediction
ancestral sampling
The goal here is to study DDIM rigorously and carefully as a new sampler built on top of the DDPM training setup.
We will keep notation consistent with standard DDPM notation:
\(x_0\): clean sample
\(x_t\): noisy sample at timestep \(t\)
\(\alpha_t = 1 - \beta_t\)
\(\bar\alpha_t = \prod_{s=1}^t \alpha_s\)
\(\epsilon_\theta(x_t,t)\): model-predicted noise
\(\hat x_0\): reconstructed clean sample estimate
\(v_\theta(x_t,t)\): velocity prediction, when used
The notebook is structured as a technical tutorial:
prerequisites beyond DDPM
DDPM sampling recap
DDIM intuition
DDIM derivation
deterministic vs stochastic DDIM
timestep sub-sampling
classifier guidance
classifier-free guidance
implementation notes
common confusions
summary and comparison
Prerequisites Beyond DDPM#
To understand DDIM properly, we need a few ideas beyond standard DDPM derivations.
1. What part of DDPM sampling is stochastic?#
In ancestral DDPM sampling, the reverse transition is Gaussian:
In the common scalar-variance case,
so one reverse step is
Thus the fresh Gaussian term \(\sigma_t z\) is the explicit source of stochasticity during reverse sampling.
2. What quantity determines randomness?#
The amount of randomness is controlled by the reverse variance:
In standard DDPM ancestral sampling, this is typically chosen as the posterior variance
So the reverse randomness at each step is determined by the scale of \(\sigma_t\).
3. Deterministic vs stochastic trajectories#
A reverse generative trajectory is the chain
If every step includes fresh noise, the trajectory is stochastic.
If no fresh noise is added, the trajectory is deterministic once \(x_T\) is fixed.
DDIM will let us continuously interpolate between these cases.
5. Relation between \(\epsilon\)-prediction and \(x_0\)-prediction#
From
we solve for \(x_0\):
Replacing the unknown \(\epsilon\) by the model prediction gives
This clean/noise decomposition is the key bridge from DDPM to DDIM.
6. Why DDIM is a family of samplers#
DDIM is not just one update rule. It is a family parameterized by:
a timestep subsequence
a stochasticity control parameter \(\eta\)
This means:
\(\eta = 0\) gives deterministic DDIM
\(\eta > 0\) gives stochastic DDIM
using all steps gives dense sampling
using a sparse timestep subset gives accelerated sampling
DDPM Sampling Recap#
We now recall the exact DDPM formulas needed to derive DDIM.
Forward marginal#
The closed-form forward marginal is
which is equivalent to
Reconstructing \(\hat x_0\)#
Given a model prediction \(\epsilon_\theta(x_t,t)\), we reconstruct the clean sample as
This is obtained by solving the forward corruption equation for \(x_0\).
Posterior mean in DDPM#
The exact posterior is
where
and
Replacing \(x_0\) by \(\hat x_0\) gives the learned DDPM mean.
DDPM reverse mean in \(\epsilon\)-parameterization#
A standard form for the learned reverse mean is
This can also be rewritten in the very important signal/noise form
Ancestral DDPM update#
The full ancestral sampling step is
often with
Thus DDPM sampling is stochastic because it injects fresh noise at every reverse step.
# Verify numerically that the two DDPM mean formulas match
T = 100
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
t = 60
alpha_t = alphas[t - 1]
alpha_bar_t = alpha_bars[t - 1]
alpha_bar_prev = get_alpha_bar(alpha_bars, t - 1)
x_t = np.array([0.7])
eps_pred = np.array([-0.4])
x0_hat = x0_from_eps(x_t, eps_pred, alpha_bar_t)
mu1 = ddpm_mean_from_eps(x_t, eps_pred, alpha_t, alpha_bar_t)
mu2 = ddpm_mean_from_x0_eps(x0_hat, eps_pred, alpha_t, alpha_bar_t, alpha_bar_prev)
print("x0_hat =", x0_hat)
print("DDPM mean form 1 =", mu1)
print("DDPM mean form 2 =", mu2)
print("Absolute difference =", np.abs(mu1 - mu2))
x0_hat = [1.10414082]
DDPM mean form 1 = [0.71294411]
DDPM mean form 2 = [0.71294411]
Absolute difference = [2.22044605e-16]
DDIM Intuition#
DDIM starts from a simple but powerful observation.
At timestep \(t\), the model gives us an estimate of the clean sample:
If we now want a sample at another noise level, say timestep \(s < t\), then the forward noising formula suggests the generic decomposition
So if we replace \(x_0\) by \(\hat x_0\) and use the model’s inferred direction \(\epsilon_\theta(x_t,t)\), we can directly synthesize a point at the lower noise level.
This is the core geometric idea of DDIM:
estimate the clean content
move to a new noise level
optionally inject fresh noise
otherwise follow a deterministic trajectory
Big picture: what changes from DDPM?#
DDPM uses the posterior-inspired ancestral step
DDIM instead uses a more direct reparameterized step that explicitly separates:
the clean-content term
the model-predicted direction term
the optional fresh-noise term
This makes timestep skipping natural and allows deterministic generation.
Why DDPM sampling is slow#
DDPM ancestral sampling usually uses many small reverse steps. Each step requires a neural network evaluation. Therefore inference is expensive.
DDIM accelerates sampling by allowing transitions between a chosen subset of timesteps, often dramatically reducing the number of function evaluations.
What does “implicit” mean here?#
In deterministic DDIM, generation becomes a deterministic transformation from initial noise \(x_T\) to final sample \(x_0\):
This no longer relies on explicit ancestral resampling at every reverse transition. The model defines an implicit denoising trajectory rather than sampling each reverse conditional in the original DDPM ancestral way.
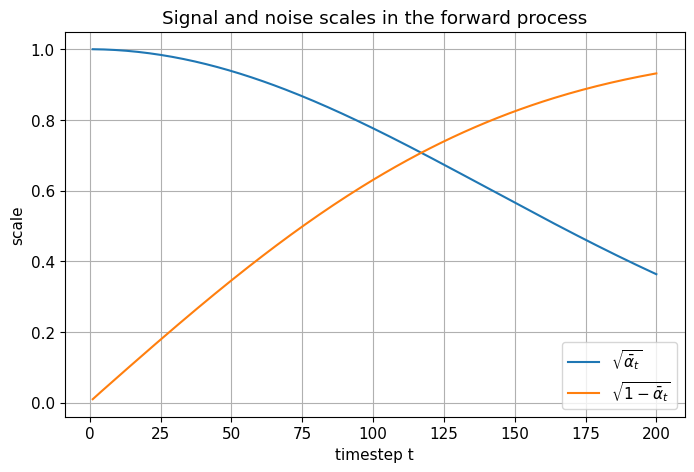
# Visualize alpha_bar_t and noise magnitude as a function of timestep
T = 200
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
timesteps = np.arange(1, T + 1)
signal_scales = np.sqrt(alpha_bars)
noise_scales = np.sqrt(1.0 - alpha_bars)
plt.figure()
plt.plot(timesteps, signal_scales, label=r'$\sqrt{\bar{\alpha}_t}$')
plt.plot(timesteps, noise_scales, label=r'$\sqrt{1-\bar{\alpha}_t}$')
plt.xlabel("timestep t")
plt.ylabel("scale")
plt.title("Signal and noise scales in the forward process")
plt.legend()
plt.show()
DDIM Derivation#
We now derive the DDIM update carefully.
Step 1: Start from the noisy-sample identity#
At timestep \(t\),
Solving for \(x_0\) gives
Replacing the unknown \(\epsilon\) by the network prediction yields
Step 2: Ask what a point at timestep \(t-1\) should look like#
At timestep \(t-1\), the forward marginal would have the form
DDIM constructs a reverse step by using the estimated clean sample \(\hat x_0\) and decomposing the remaining noise budget into:
a model-aligned direction term
an optional fresh Gaussian term
So we write
This is the generalized DDIM update.
Step 3: Why does the coefficient of \(\epsilon_\theta\) look like that?#
At timestep \(t-1\), the total variance budget should be
DDIM splits this budget into two parts:
So:
the direction term gets variance magnitude \(1-\bar\alpha_{t-1}-\sigma_t^2\)
the fresh-noise term gets variance magnitude \(\sigma_t^2\)
This explains the structure
Step 4: Generalized DDIM variance scale#
DDIM defines
This introduces the stochasticity parameter \(\eta\).
\(\eta = 0\) gives deterministic DDIM
\(\eta > 0\) gives stochastic DDIM
\(\eta = 1\) matches DDPM posterior variance for adjacent steps
Step 5: Verify the DDPM consistency when \(\eta = 1\)#
For adjacent steps,
So
Thus DDIM recovers the DDPM posterior variance when \(\eta = 1\).
Step 6: Deterministic DDIM#
If \(\eta = 0\), then \(\sigma_t = 0\), and the update reduces to
No fresh noise is injected, so the trajectory is deterministic given the initial noise \(x_T\).
Step 7: Write DDIM fully in terms of \(x_t\) and \(\epsilon_\theta\)#
Substitute
into the DDIM update:
Expanding the first term gives
Grouping the \(\epsilon_\theta\) terms gives
This is an explicit DDIM update in terms of \(x_t\) and the predicted noise.
Step 8: Why DDIM differs from ancestral DDPM#
DDPM ancestral sampling uses the posterior-inspired mean and fresh noise at every step.
DDIM instead explicitly reconstructs \(\hat x_0\) and then reprojects to a lower-noise point using a controlled mixture of:
estimated clean content
predicted direction
optional randomness
This reparameterized viewpoint is what makes timestep skipping natural.
# Compare the DDIM sigma_t as eta varies
T = 100
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
ts = np.arange(2, T + 1)
sigma_eta0 = []
sigma_eta05 = []
sigma_eta1 = []
for t in ts:
alpha_bar_t = get_alpha_bar(alpha_bars, t)
alpha_bar_prev = get_alpha_bar(alpha_bars, t - 1)
sigma_eta0.append(ddim_sigma(alpha_bar_t, alpha_bar_prev, eta=0.0))
sigma_eta05.append(ddim_sigma(alpha_bar_t, alpha_bar_prev, eta=0.5))
sigma_eta1.append(ddim_sigma(alpha_bar_t, alpha_bar_prev, eta=1.0))
plt.figure()
plt.plot(ts, sigma_eta0, label=r'$\eta=0$')
plt.plot(ts, sigma_eta05, label=r'$\eta=0.5$')
plt.plot(ts, sigma_eta1, label=r'$\eta=1$')
plt.xlabel("timestep t")
plt.ylabel(r'$\sigma_t$')
plt.title("DDIM stochasticity scale as a function of eta")
plt.legend()
plt.show()
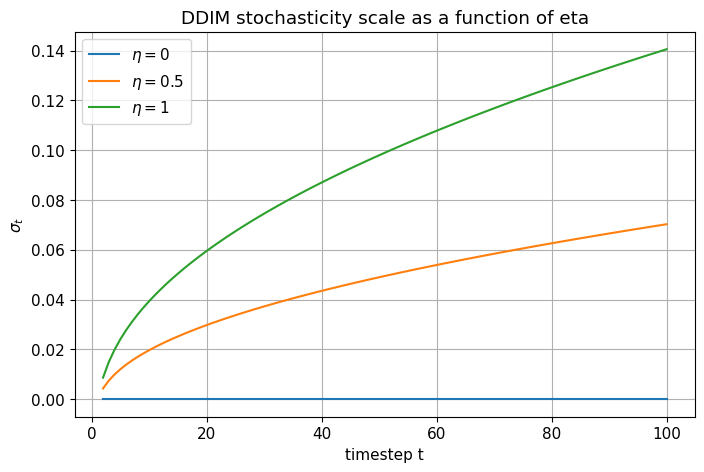
Deterministic vs Stochastic DDIM#
The DDIM update is
The only source of fresh randomness is the final term \(\sigma_t z\).
Deterministic DDIM#
When \(\eta = 0\),
so
This means:
no fresh noise is injected
the trajectory is fully determined by the starting point \(x_T\)
trajectories are often smoother
interpolation and inversion become more natural
Stochastic DDIM#
When \(\eta > 0\),
Now the reverse process has two distinct sources of uncertainty:
the initial random sample \(x_T\)
fresh per-step noise \(\sigma_t z\)
As \(\eta\) increases, trajectories become less deterministic and more diverse.
Trajectory smoothness intuition#
In deterministic DDIM, the sequence evolves by repeatedly:
estimating the same underlying clean content
re-expressing that content at progressively lower noise levels
So the latent path is often smoother than in DDPM ancestral sampling, which injects fresh perturbations at every step.
# 1D pedagogical trajectory comparison: deterministic vs stochastic DDIM
T = 80
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
rng = np.random.default_rng(7)
def true_eps_model(x_t, t, x0_true, alpha_bars):
alpha_bar_t = get_alpha_bar(alpha_bars, t)
return eps_from_x0(x_t, np.array([x0_true]), alpha_bar_t)
def simulate_ddim_trajectory(x0_true=2.0, xT=None, eta=0.0, T=80, seed=0):
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
rng = np.random.default_rng(seed)
if xT is None:
x_t = rng.normal(size=(1,))
else:
x_t = np.array([xT], dtype=np.float64)
traj = [(T, x_t.item())]
for t in range(T, 0, -1):
alpha_bar_t = get_alpha_bar(alpha_bars, t)
alpha_bar_prev = get_alpha_bar(alpha_bars, t - 1)
eps_pred = true_eps_model(x_t, t, x0_true, alpha_bars)
x_t, _, _ = ddim_step_from_eps(x_t, eps_pred, alpha_bar_t, alpha_bar_prev, eta=eta, rng=rng)
traj.append((t - 1, x_t.item()))
return traj
traj_det = simulate_ddim_trajectory(eta=0.0, seed=5)
traj_sto = simulate_ddim_trajectory(eta=1.0, seed=5)
plt.figure()
plt.plot([t for t, x in traj_det], [x for t, x in traj_det], label="DDIM eta=0")
plt.plot([t for t, x in traj_sto], [x for t, x in traj_sto], label="DDIM eta=1")
plt.gca().invert_xaxis()
plt.xlabel("timestep")
plt.ylabel("state value")
plt.title("1D trajectories: deterministic vs stochastic DDIM")
plt.legend()
plt.show()
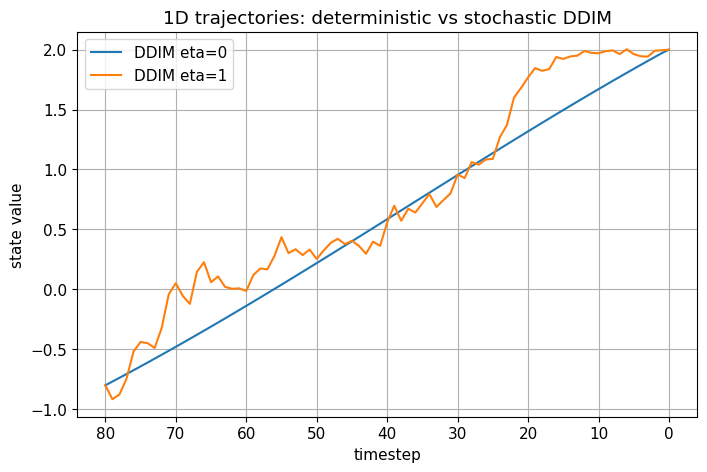
Timestep Sub-Sampling#
One of the main practical advantages of DDIM is that it supports reduced-step sampling naturally.
Instead of using every timestep
we choose a subsequence
At each step, we move directly from \(x_{\tau_i}\) to \(x_{\tau_{i+1}}\).
General DDIM update for skipped steps#
Let \(t = \tau_i\) and \(s = \tau_{i+1}\) with \(s < t\). Then the generalized DDIM update is
where
This is the skipped-step analogue of the adjacent-step DDIM update.
Why skipping works#
Once we have \(\hat x_0\), we can synthesize a point at another noise level because the forward marginal form at timestep \(s\) is
DDIM uses the estimated clean sample and the model-predicted direction to jump directly between noise levels.
This is why DDIM is much more naturally compatible with accelerated sampling than ancestral DDPM.
What changes mathematically from DDPM?#
In ancestral DDPM, the sampler is tied closely to adjacent-step posterior transitions.
In DDIM, the update is reparameterized in terms of:
\(\hat x_0\)
the target cumulative noise level \(\bar\alpha_s\)
a chosen stochasticity level \(\eta\)
This makes step skipping a first-class part of the sampler.
# Compare dense vs sparse DDIM timestep sequences
seq1, traj1 = simulate_ddim_subsampled(T=100, num_steps=101, eta=0.0, seed=3)
seq2, traj2 = simulate_ddim_subsampled(T=100, num_steps=20, eta=0.0, seed=3)
seq3, traj3 = simulate_ddim_subsampled(T=100, num_steps=10, eta=0.0, seed=3)
plt.figure()
plt.plot([t for t, x in traj1], [x for t, x in traj1], marker='o', ms=2, label='101 steps')
plt.plot([t for t, x in traj2], [x for t, x in traj2], marker='o', ms=4, label='20 steps')
plt.plot([t for t, x in traj3], [x for t, x in traj3], marker='o', ms=5, label='10 steps')
plt.gca().invert_xaxis()
plt.xlabel("timestep")
plt.ylabel("state value")
plt.title("DDIM with different timestep subsets")
plt.legend()
plt.show()
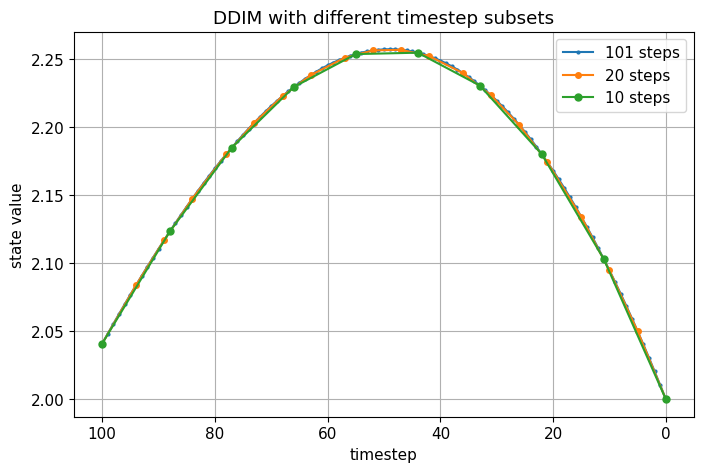
How \(\hat x_0\) and \(\epsilon_\theta\) Determine the Update#
A very important practical point is that the reverse step can be written in multiple equivalent parameterizations.
From \(\epsilon_\theta\) to \(\hat x_0\)#
If the model predicts noise, then
Then DDIM uses
From \(\hat x_0\) to \(\epsilon_\theta\)#
If the model instead predicts \(\hat x_0\) directly, then the implied noise is
Then the same DDIM formula applies after substitution.
Why this matters#
This shows that DDIM is fundamentally a sampling framework, not a commitment to only one network output parameterization.
As long as we can consistently recover:
\(\hat x_0\)
and/or the denoising direction \(\hat\epsilon\)
we can execute the DDIM update.
# Demonstrate consistency between x0-prediction and epsilon-prediction for one DDIM step
T = 100
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
t = 70
alpha_bar_t = get_alpha_bar(alpha_bars, t)
alpha_bar_prev = get_alpha_bar(alpha_bars, t - 1)
x_t = np.array([1.2])
eps_pred = np.array([-0.35])
x0_hat = x0_from_eps(x_t, eps_pred, alpha_bar_t)
eps_recovered = eps_from_x0(x_t, x0_hat, alpha_bar_t)
rng = np.random.default_rng(0)
x_prev_eps, _, sigma_eps = ddim_step_from_eps(x_t, eps_pred, alpha_bar_t, alpha_bar_prev, eta=0.0, rng=rng)
rng = np.random.default_rng(0)
x_prev_x0, _, sigma_x0 = ddim_step_from_x0(x_t, x0_hat, alpha_bar_t, alpha_bar_prev, eta=0.0, rng=rng)
print("x0_hat =", x0_hat)
print("eps recovered from x0_hat =", eps_recovered)
print("x_prev from eps =", x_prev_eps)
print("x_prev from x0 =", x_prev_x0)
print("difference =", np.abs(x_prev_eps - x_prev_x0))
x0_hat = [1.81682758]
eps recovered from x0_hat = [-0.35]
x_prev from eps = [1.21244742]
x_prev from x0 = [1.21244742]
difference = [0.]
Classifier Guidance#
We now discuss conditional guidance after DDIM itself is fully established.
Score decomposition#
For class-conditional generation with label \(y\), Bayes’ rule gives
Differentiate with respect to \(x_t\):
So the conditional score equals the unconditional score plus a classifier gradient term.
Guided score#
If \(s_\theta(x_t,t)\) denotes the unconditional reverse score, classifier guidance defines
where:
\(p_\phi(y\mid x_t,t)\) is a classifier trained on noisy samples
\(w\) is the guidance scale
Convert to \(\epsilon\)-prediction form#
For variance-preserving diffusion, the score and noise prediction are related by
Therefore the guided \(\epsilon\) prediction becomes
This is the quantity used inside DDPM or DDIM sampling.
Connection to DDIM#
Once we have \(\epsilon_{\text{guided}}\), we simply replace \(\epsilon_\theta\) by \(\epsilon_{\text{guided}}\) in the DDIM step:
and
So guidance is orthogonal to the DDPM-vs-DDIM distinction: it modifies the denoising direction used by either sampler.
Classifier-Free Guidance#
Classifier-free guidance avoids training a separate classifier.
Basic idea#
During training, the diffusion model is trained both:
conditionally on \(y\)
unconditionally, by dropping the condition with some probability
So the same model learns:
\(\epsilon_\theta(x_t,t,y)\)
\(\epsilon_\theta(x_t,t,\varnothing)\)
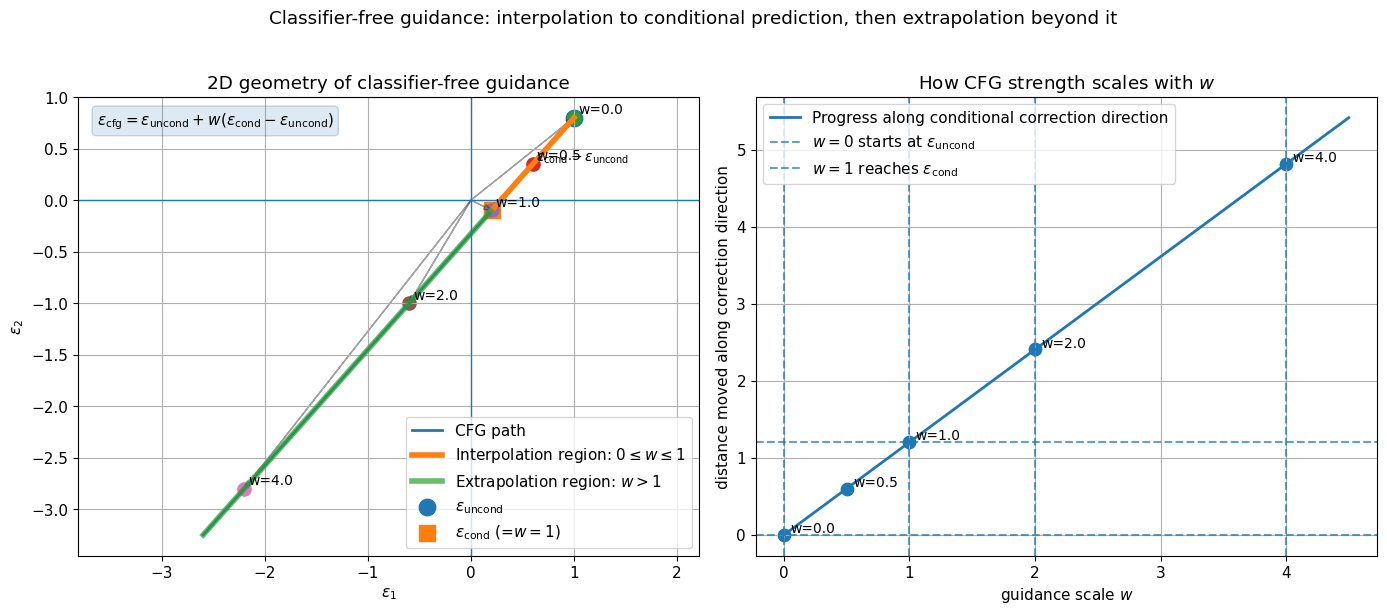
CFG formula#
The standard classifier-free guidance combination is
Equivalent form:
Interpretation#
\(\epsilon_\theta(x_t,t,\varnothing)\) is the unconditional denoising direction
\(\epsilon_\theta(x_t,t,y)\) is the conditional denoising direction
the difference estimates the conditional correction
\(w\) amplifies or attenuates that correction
Special cases:
\(w = 0\): unconditional sampling
\(w = 1\): ordinary conditional sampling
\(w > 1\): extrapolated guidance, often stronger prompt/class alignment
Tradeoff between fidelity and diversity#
As guidance scale \(w\) increases:
condition alignment usually improves
diversity often decreases
oversharpening or artifacts may appear at very high scales
This tradeoff exists for both DDPM and DDIM samplers.
In deterministic or low-noise DDIM, strong guidance can make trajectories especially rigid.
Algorithm: DDIM Sampling#
Below is the algorithmic structure for DDIM sampling.
Inputs#
trained denoiser \(\epsilon_\theta(x_t,t)\)
noise schedule \(\{\alpha_t\}_{t=1}^T\)
cumulative schedule \(\bar\alpha_t = \prod_{s=1}^t \alpha_s\)
timestep subsequence \(\tau_0 = T > \tau_1 > \cdots > \tau_S = 0\)
stochasticity parameter \(\eta\)
initial noise \(x_{\tau_0} \sim \mathcal N(0,I)\)
DDIM sampling algorithm#
For \(i = 0, 1, \dots, S-1\):
set \(t = \tau_i\) and \(s = \tau_{i+1}\)
predict noise:
\[ \epsilon_t = \epsilon_\theta(x_t, t) \]reconstruct clean sample:
\[ \hat x_0 = \frac{x_t - \sqrt{1-\bar\alpha_t}\,\epsilon_t}{\sqrt{\bar\alpha_t}} \]compute stochasticity scale:
\[ \sigma_{t\to s} = \eta \sqrt{ \frac{1-\bar\alpha_s}{1-\bar\alpha_t} \left( 1-\frac{\bar\alpha_t}{\bar\alpha_s} \right) } \]sample \(z \sim \mathcal N(0,I)\) if \(\eta > 0\)
update:
\[ x_s = \sqrt{\bar\alpha_s}\,\hat x_0 + \sqrt{1-\bar\alpha_s-\sigma_{t\to s}^2}\,\epsilon_t + \sigma_{t\to s} z \]
Output \(x_0\).
Important interpretation#
This algorithm differs from ancestral DDPM in two ways:
it is written in reparameterized form using \(\hat x_0\)
it naturally allows sparse timestep subsets
Algorithm: DDIM Sampling with Classifier-Free Guidance#
Now we include classifier-free guidance inside DDIM.
Inputs#
conditional denoiser outputs:
\(\epsilon_\theta(x_t,t,\varnothing)\)
\(\epsilon_\theta(x_t,t,y)\)
guidance scale \(w\)
all DDIM inputs from the previous section
CFG-DDIM algorithm#
For each reverse step from \(t\) to \(s\):
compute unconditional prediction:
\[ \epsilon_u = \epsilon_\theta(x_t,t,\varnothing) \]compute conditional prediction:
\[ \epsilon_c = \epsilon_\theta(x_t,t,y) \]combine using classifier-free guidance:
\[ \epsilon_{\text{cfg}} = \epsilon_u + w(\epsilon_c - \epsilon_u) \]reconstruct clean sample:
\[ \hat x_0 = \frac{x_t - \sqrt{1-\bar\alpha_t}\,\epsilon_{\text{cfg}}}{\sqrt{\bar\alpha_t}} \]compute \(\sigma_{t\to s}(\eta)\)
update:
\[ x_s = \sqrt{\bar\alpha_s}\,\hat x_0 + \sqrt{1-\bar\alpha_s-\sigma_{t\to s}^2}\,\epsilon_{\text{cfg}} + \sigma_{t\to s} z \]
Output the final \(x_0\).
Interpretation#
CFG changes the denoising direction before the sampler update is applied.
The DDIM structure remains the same; only the effective \(\epsilon\) prediction changes.
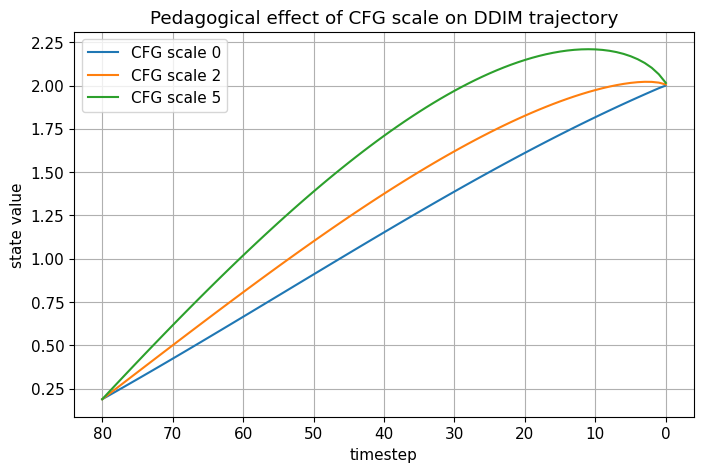
# Simplified pedagogical DDIM + CFG trajectory demo in 1D
T = 80
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
def simulate_cfg_ddim_trajectory(x0_true=2.0, cond_bias=-0.3, guidance_scale=0.0, eta=0.0, seed=0):
rng = np.random.default_rng(seed)
x_t = rng.normal(size=(1,))
traj = [(T, x_t.item())]
for t in range(T, 0, -1):
alpha_bar_t = get_alpha_bar(alpha_bars, t)
alpha_bar_prev = get_alpha_bar(alpha_bars, t - 1)
# unconditional "teacher"
eps_uncond = eps_from_x0(x_t, np.array([x0_true]), alpha_bar_t)
# conditional branch = perturbed direction in a pedagogical way
eps_cond = eps_uncond + cond_bias
eps_guided = cfg_eps(eps_uncond, eps_cond, guidance_scale)
x_t, _, _ = ddim_step_from_eps(x_t, eps_guided, alpha_bar_t, alpha_bar_prev, eta=eta, rng=rng)
traj.append((t - 1, x_t.item()))
return traj
traj_w0 = simulate_cfg_ddim_trajectory(guidance_scale=0.0, eta=0.0, seed=2)
traj_w2 = simulate_cfg_ddim_trajectory(guidance_scale=2.0, eta=0.0, seed=2)
traj_w5 = simulate_cfg_ddim_trajectory(guidance_scale=5.0, eta=0.0, seed=2)
plt.figure()
plt.plot([t for t, x in traj_w0], [x for t, x in traj_w0], label='CFG scale 0')
plt.plot([t for t, x in traj_w2], [x for t, x in traj_w2], label='CFG scale 2')
plt.plot([t for t, x in traj_w5], [x for t, x in traj_w5], label='CFG scale 5')
plt.gca().invert_xaxis()
plt.xlabel("timestep")
plt.ylabel("state value")
plt.title("Pedagogical effect of CFG scale on DDIM trajectory")
plt.legend()
plt.show()
Compact Comparison: DDPM vs DDIM vs DDIM + CFG#
This section summarizes the practical differences.
DDPM ancestral sampling#
Update:
Characteristics:
stochastic at every step
closely tied to the posterior structure
usually many steps
good diversity due to repeated noise injection
DDIM#
Update:
Characteristics:
can be deterministic when \(\eta=0\)
naturally supports timestep skipping
often much faster
often smoother latent trajectories
diversity may reduce when \(\eta\) is very small
DDIM + CFG#
Update uses guided noise prediction
and then the usual DDIM formula.
Characteristics:
inherits DDIM speed and controllability
improves condition fidelity
may reduce diversity as guidance scale increases
strong guidance can produce rigid trajectories or artifacts
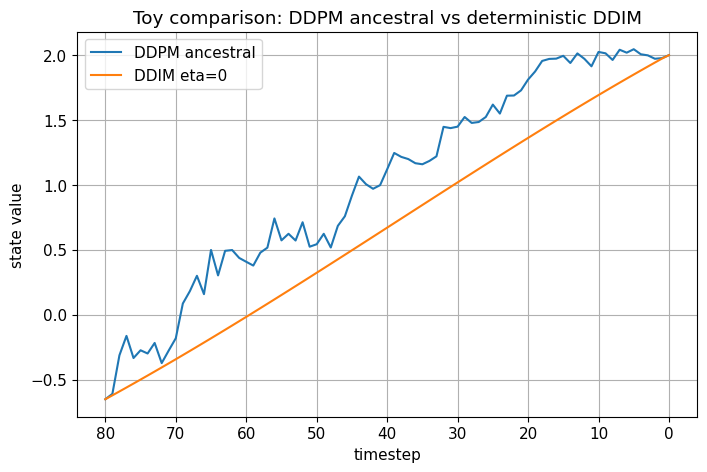
# Compare DDPM-style stochastic update and DDIM deterministic update in a 1D toy setting
T = 80
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
def simulate_ddpm_ancestral_trajectory(x0_true=2.0, T=80, seed=0):
rng = np.random.default_rng(seed)
x_t = rng.normal(size=(1,))
traj = [(T, x_t.item())]
for t in range(T, 0, -1):
beta_t = betas[t - 1]
alpha_t = alphas[t - 1]
alpha_bar_t = get_alpha_bar(alpha_bars, t)
alpha_bar_prev = get_alpha_bar(alpha_bars, t - 1)
eps_pred = eps_from_x0(x_t, np.array([x0_true]), alpha_bar_t)
mu = ddpm_mean_from_eps(x_t, eps_pred, alpha_t, alpha_bar_t)
sigma = np.sqrt(posterior_variance(beta_t, alpha_bar_t, alpha_bar_prev))
x_t = mu + sigma * rng.normal(size=(1,))
traj.append((t - 1, x_t.item()))
return traj
traj_ddpm = simulate_ddpm_ancestral_trajectory(seed=4)
traj_ddim = simulate_ddim_trajectory(eta=0.0, seed=4)
plt.figure()
plt.plot([t for t, x in traj_ddpm], [x for t, x in traj_ddpm], label='DDPM ancestral')
plt.plot([t for t, x in traj_ddim], [x for t, x in traj_ddim], label='DDIM eta=0')
plt.gca().invert_xaxis()
plt.xlabel("timestep")
plt.ylabel("state value")
plt.title("Toy comparison: DDPM ancestral vs deterministic DDIM")
plt.legend()
plt.show()
Implementation Notes#
This section summarizes the key implementation choices.
1. The model can predict different quantities#
The sampler may be implemented using:
\(\epsilon\)-prediction
\(x_0\)-prediction
\(v\)-prediction
But the DDIM step is easiest to think about in terms of \(\hat x_0\) and \(\hat\epsilon\).
2. Use a helper to reconstruct \(\hat x_0\)#
For \(\epsilon\)-prediction:
This helper is central and should be implemented carefully.
3. Timestep skipping requires a chosen sequence#
Instead of all timesteps, select a sequence such as:
uniform in index
quadratic spacing
custom hand-designed schedules
The DDIM formulas use the corresponding \(\bar\alpha_t\) values directly.
4. Deterministic DDIM is often used for inversion/editing#
Because the mapping is deterministic given the initial noise, DDIM is often used when we want more stable trajectories, interpolation, or inversion-style reasoning.
5. Guidance is inserted before the sampler update#
For classifier-free guidance:
get unconditional prediction
get conditional prediction
combine them to get \(\epsilon_{\text{cfg}}\)
use \(\epsilon_{\text{cfg}}\) inside the DDIM update
So guidance modifies the denoiser output, not the structural form of the DDIM formula.
6. Numerical stability#
In practice, implementations often:
clip or threshold \(\hat x_0\)
ensure square-root arguments are nonnegative
use precomputed tensors for \(\alpha_t\) and \(\bar\alpha_t\)
carefully handle timestep indexing conventions
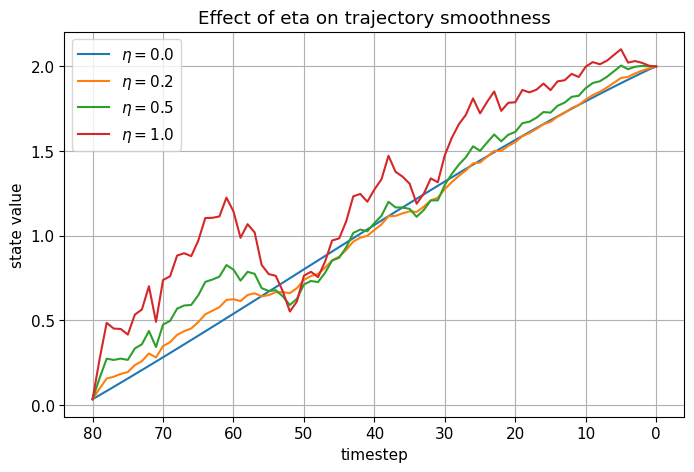
# Show how eta affects trajectory smoothness by plotting several trajectories from the same start
etas = [0.0, 0.2, 0.5, 1.0]
plt.figure()
for eta in etas:
traj = simulate_ddim_trajectory(eta=eta, seed=11)
plt.plot([t for t, x in traj], [x for t, x in traj], label=fr'$\eta={eta}$')
plt.gca().invert_xaxis()
plt.xlabel("timestep")
plt.ylabel("state value")
plt.title("Effect of eta on trajectory smoothness")
plt.legend()
plt.show()
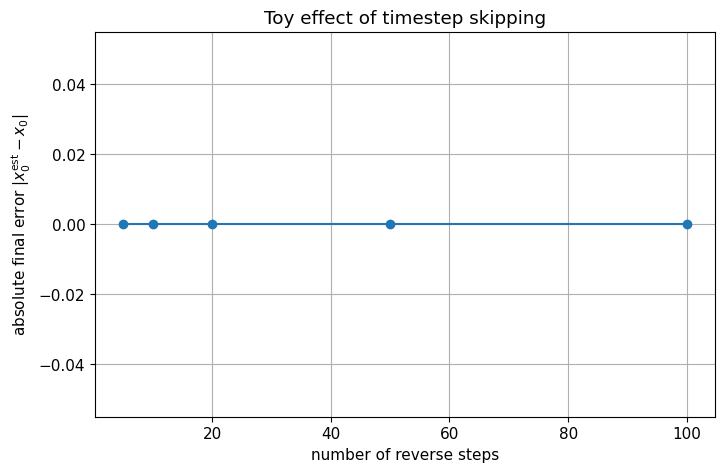
# Visualize the effect of timestep skipping on final error in a toy setting
T = 100
x0_true = 2.0
step_counts = [100, 50, 20, 10, 5]
final_errors = []
for num_steps in step_counts:
_, traj = simulate_ddim_subsampled(x0_true=x0_true, T=T, num_steps=num_steps, eta=0.0, seed=13)
x0_est = traj[-1][1]
final_errors.append(abs(x0_est - x0_true))
plt.figure()
plt.plot(step_counts, final_errors, marker='o')
plt.xlabel("number of reverse steps")
plt.ylabel(r"absolute final error $|x_0^{\mathrm{est}} - x_0|$")
plt.title("Toy effect of timestep skipping")
plt.show()
Common Confusions#
1. Is DDIM a new training objective?#
Not necessarily. The key practical point is that DDIM reuses the same denoiser trained under the DDPM-style objective. What changes is the sampler.
2. Is DDIM just DDPM with no noise?#
That is only partly true. Deterministic DDIM is the \(\eta=0\) limit, but DDIM is more generally a family of reparameterized samplers that also supports arbitrary timestep skipping.
3. Why does deterministic DDIM still generate diverse samples?#
Because the initial state \(x_T\) is still sampled from a random Gaussian. The reverse path is deterministic conditioned on this initial point, but the overall generative model remains random through its starting noise.
4. Why is DDIM often said to be non-Markovian?#
The main idea is that DDIM corresponds to a broader process family that preserves the same marginals \(q(x_t\mid x_0)\) while not being tied to the original DDPM ancestral Markov chain interpretation.
5. Why do smoother trajectories appear in DDIM?#
Because deterministic or low-noise DDIM does not inject fresh Gaussian perturbations at every step. Instead, it repeatedly projects the estimated clean content to lower-noise levels.
6. Is guidance specific to DDIM?#
No. Guidance modifies the denoising direction and can be used with DDPM, DDIM, and many other diffusion samplers.
7. Why can very large guidance scale hurt samples?#
Because it over-amplifies the conditional correction. This usually improves fidelity to the condition but can reduce diversity and produce unnatural or oversharpened outputs.
Summary#
We can now summarize the full notebook in a compact way.
Core DDIM idea#
Given a noisy point \(x_t\), use the denoiser to reconstruct
Then move to a lower noise level using
What DDIM changes relative to DDPM#
DDPM:
ancestral posterior-style sampling
fresh noise every step
often many reverse steps
DDIM:
reparameterized update via \(\hat x_0\)
optional stochasticity controlled by \(\eta\)
natural timestep skipping
deterministic generation when \(\eta = 0\)
Why DDIM is useful#
DDIM is important because it offers:
faster sampling
smoother trajectories
deterministic paths for inversion/interpolation
compatibility with guidance methods
Final conceptual takeaway#
DDIM should be understood as a sampler family built on top of the DDPM denoiser.
The model training can stay the same, while the reverse-time generation path becomes more flexible, faster, and in special cases deterministic.
# ============================================================
# Main tutorial: easier data + weaker network
# ============================================================
# ----------------------------
# 1. Create and normalize easier dataset
# ----------------------------
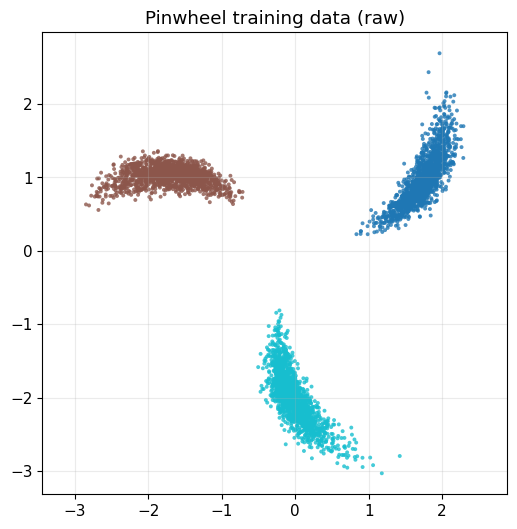
x_train_raw, y_train = make_pinwheel(
n_samples=4500,
radial_std=0.18,
tangential_std=0.06,
num_classes=3,
rate=0.18,
scale=2.0,
seed=12,
)
plot_dataset_with_labels(x_train_raw, y_train, title="Pinwheel training data (raw)")
x_train, norm_stats = normalize_data(x_train_raw)
# plot_dataset_with_labels(x_train, y_train, title="Pinwheel training data (normalized)")
# ----------------------------
# 2. Diffusion setup
# ----------------------------
T = 100
betas, alphas, alpha_bars = make_linear_beta_schedule(T)
timesteps = np.arange(1, T + 1)
# plt.figure(figsize=(7, 4))
# plt.plot(timesteps, np.sqrt(alpha_bars), label=r'$\sqrt{\bar{\alpha}_t}$')
# plt.plot(timesteps, np.sqrt(1.0 - alpha_bars), label=r'$\sqrt{1-\bar{\alpha}_t}$')
# plt.xlabel("timestep t")
# plt.ylabel("scale")
# plt.title("Forward diffusion signal/noise scales")
# plt.legend()
# plt.grid(True, alpha=0.25)
# plt.show()
# ----------------------------
# 3. Build weaker model
# ----------------------------
model = SmallDenoiserMLP(
x_dim=2,
t_dim=24,
h1=64,
h2=64,
seed=0,
)
# ----------------------------
# 4. Train model
# ----------------------------
losses = train_ddim_denoiser(
model=model,
x_train=x_train,
T=T,
alpha_bars=alpha_bars,
epochs=300,
batch_size=256,
lr=1.2e-3,
lr_decay=0.998,
grad_clip=1.0,
seed=42,
verbose_every=25,
)
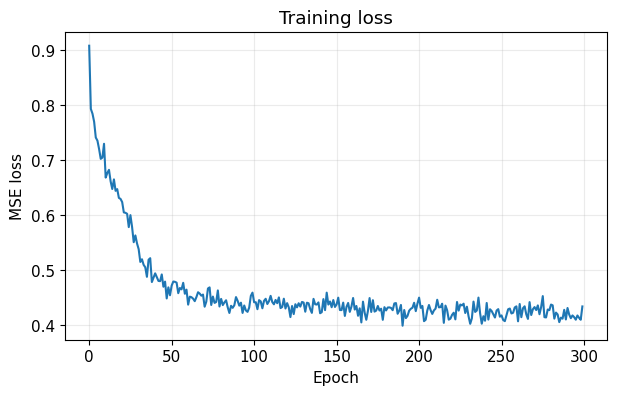
plot_training_loss(losses)
# ----------------------------
# 5. DDIM inference: deterministic
# ----------------------------
x_gen_det_norm, seq_det, path_det_norm = sample_ddim(
model=model,
n_samples=2200,
T=T,
alpha_bars=alpha_bars,
num_steps=40,
eta=0.0,
seed=123,
store_path=True,
)
x_gen_det = denormalize_data(x_gen_det_norm, norm_stats)
path_det = [denormalize_data(x, norm_stats) for x in path_det_norm]
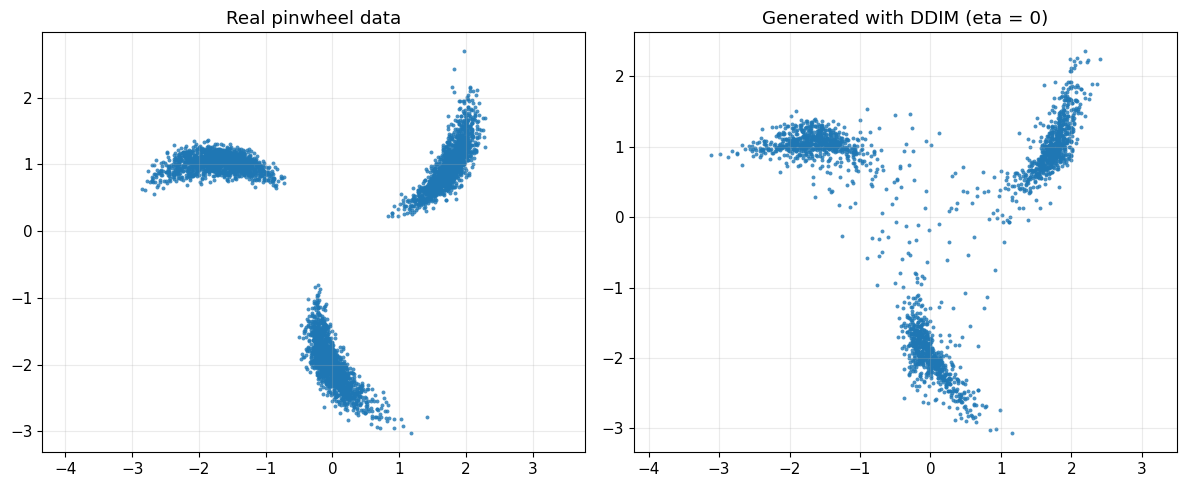
plot_real_vs_generated(
x_real=x_train_raw,
x_gen=x_gen_det,
title_real="Real pinwheel data",
title_gen="Generated with DDIM (eta = 0)"
)
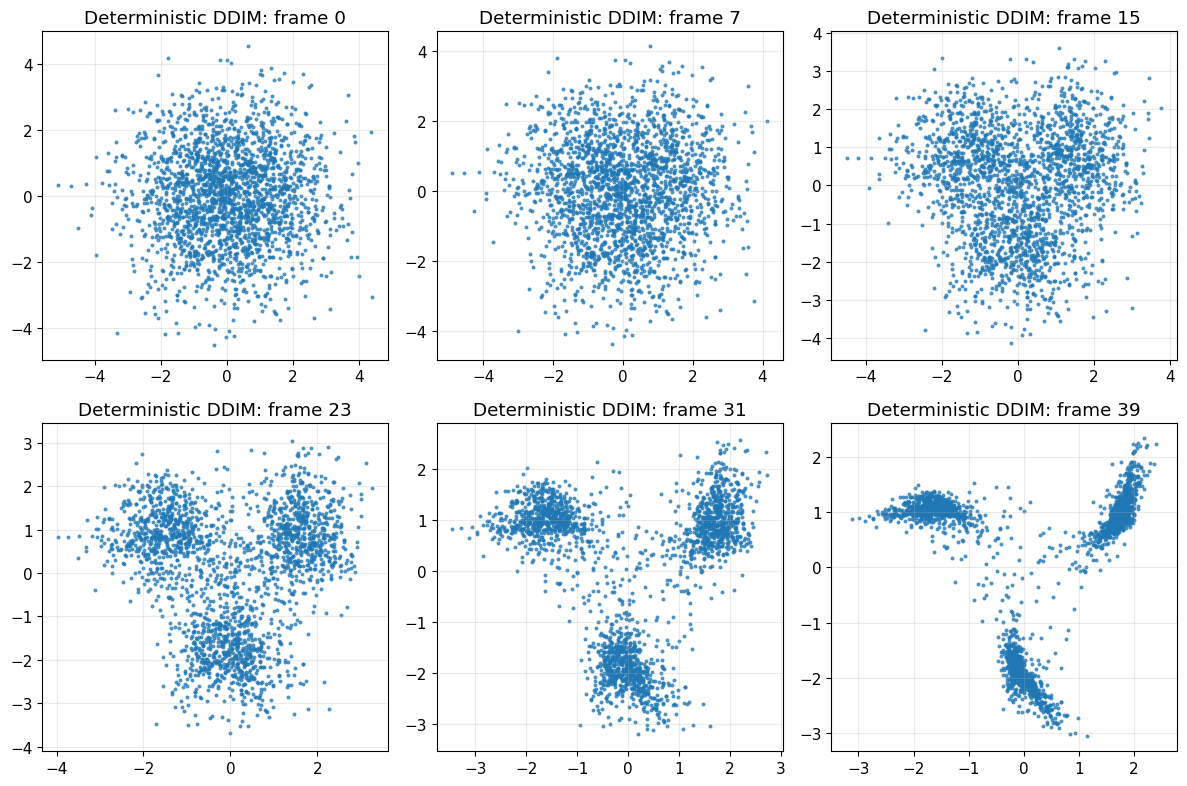
plot_sampling_path(path_det, title_prefix="Deterministic DDIM")
# ----------------------------
# 6. DDIM inference: stochastic
# ----------------------------
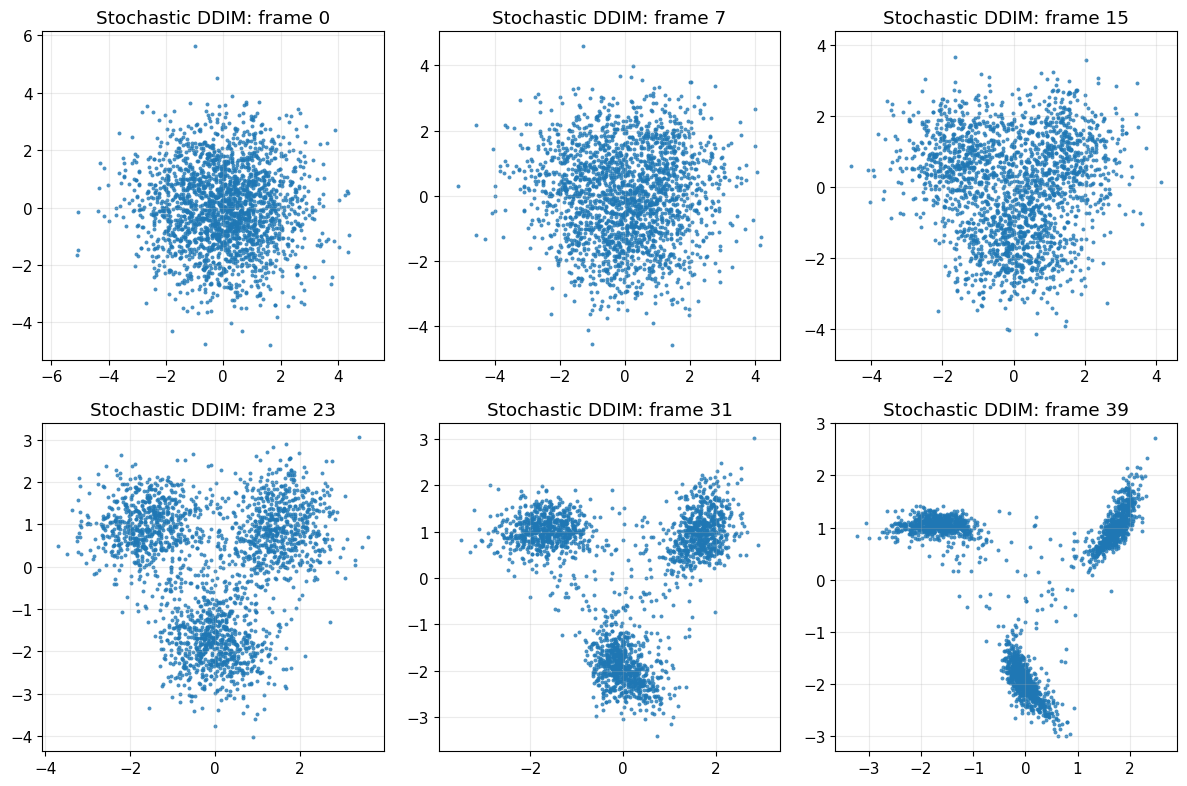
x_gen_sto_norm, seq_sto, path_sto_norm = sample_ddim(
model=model,
n_samples=2200,
T=T,
alpha_bars=alpha_bars,
num_steps=40,
eta=0.5,
seed=456,
store_path=True,
)
x_gen_sto = denormalize_data(x_gen_sto_norm, norm_stats)
path_sto = [denormalize_data(x, norm_stats) for x in path_sto_norm]
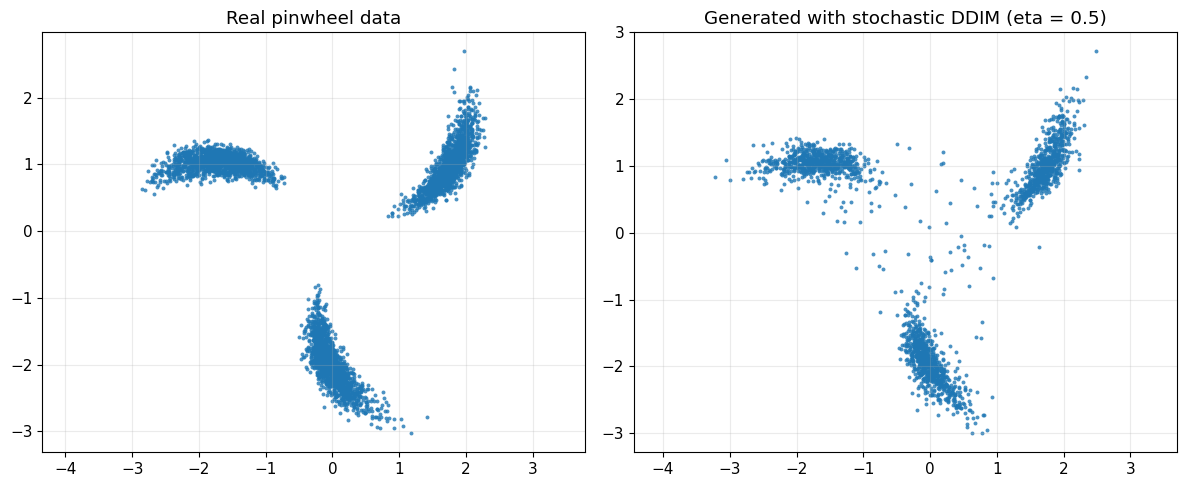
plot_real_vs_generated(
x_real=x_train_raw,
x_gen=x_gen_sto,
title_real="Real pinwheel data",
title_gen="Generated with stochastic DDIM (eta = 0.5)"
)
plot_sampling_path(path_sto, title_prefix="Stochastic DDIM")
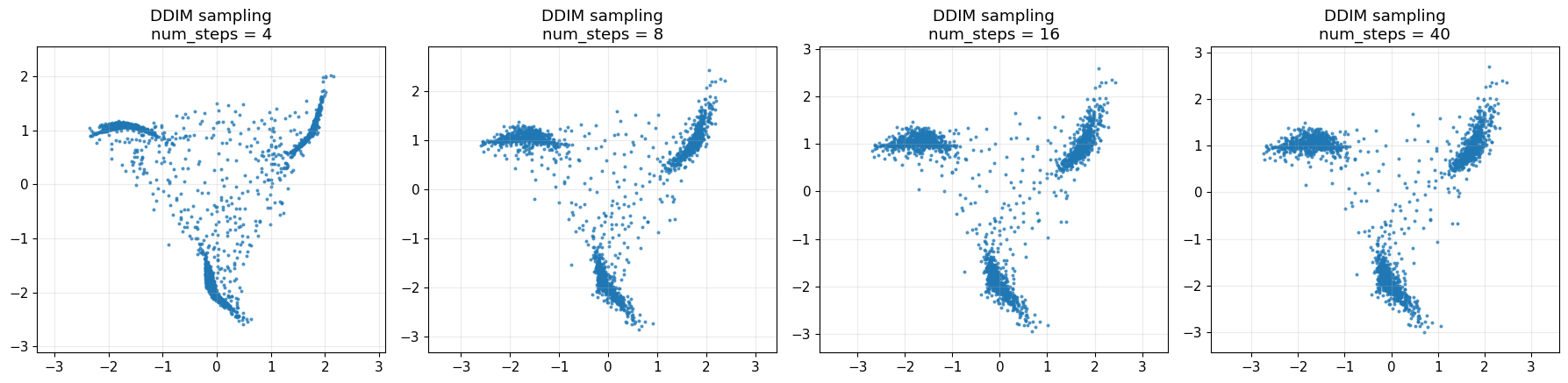
# ----------------------------
# 7. Compare different DDIM step counts
# ----------------------------
step_choices = [4, 8, 16, 40]
gen_results = []
shared_seed = 999
for num_steps in step_choices:
x_gen_norm, _, _ = sample_ddim(
model=model,
n_samples=1800,
T=T,
alpha_bars=alpha_bars,
num_steps=num_steps,
eta=0.0,
seed=shared_seed,
store_path=False,
)
x_gen = denormalize_data(x_gen_norm, norm_stats)
gen_results.append((num_steps, x_gen))
fig, axes = plt.subplots(1, len(step_choices), figsize=(18, 4.5))
for ax, (num_steps, x_gen) in zip(axes, gen_results):
ax.scatter(x_gen[:, 0], x_gen[:, 1], s=8, alpha=0.8, linewidths=0)
ax.set_title(f"DDIM sampling\nnum_steps = {num_steps}")
ax.axis("equal")
ax.grid(True, alpha=0.25)
plt.tight_layout()
plt.show()
# ----------------------------
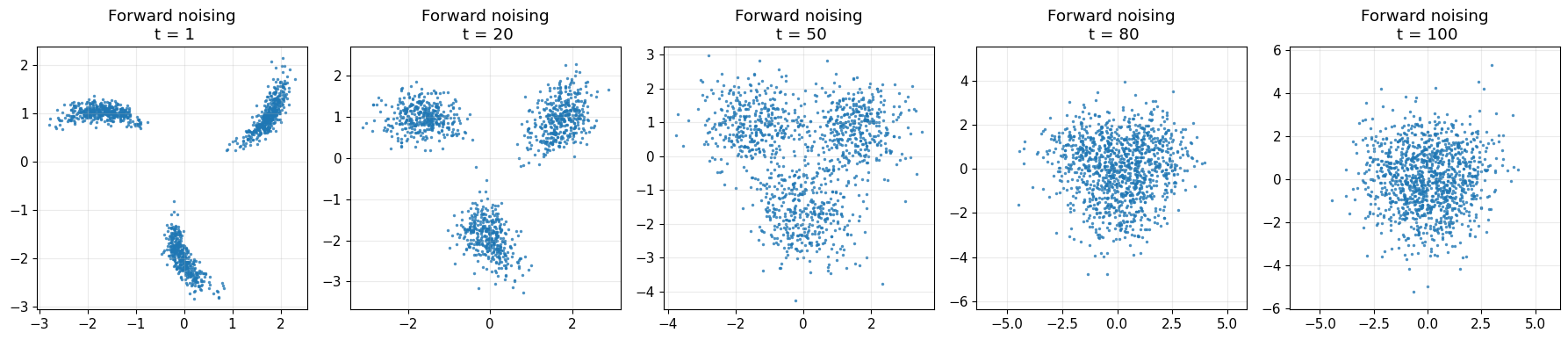
# 8. Show forward corruption examples
# ----------------------------
rng_vis = np.random.default_rng(0)
subset = x_train[:1200]
chosen_t = [1, 20, 50, 80, 100]
fig, axes = plt.subplots(1, len(chosen_t), figsize=(18, 4))
for ax, t in zip(axes, chosen_t):
t_idx = np.full(len(subset), t, dtype=int)
x_t_norm, _ = sample_q_xt_given_x0(subset, t_idx, alpha_bars, rng_vis)
x_t = denormalize_data(x_t_norm, norm_stats)
ax.scatter(x_t[:, 0], x_t[:, 1], s=6, alpha=0.8, linewidths=0)
ax.set_title(f"Forward noising\n t = {t}")
ax.axis("equal")
ax.grid(True, alpha=0.25)
plt.tight_layout()
plt.show()
Epoch 1 | loss = 0.907566 | lr = 0.001198
Epoch 25 | loss = 0.578273 | lr = 0.001141
Epoch 50 | loss = 0.454475 | lr = 0.001086
Epoch 75 | loss = 0.436877 | lr = 0.001033
Epoch 100 | loss = 0.459271 | lr = 0.000982
Epoch 125 | loss = 0.420282 | lr = 0.000934
Epoch 150 | loss = 0.433237 | lr = 0.000889
Epoch 175 | loss = 0.426662 | lr = 0.000845
Epoch 200 | loss = 0.439302 | lr = 0.000804
Epoch 225 | loss = 0.426611 | lr = 0.000765
Epoch 250 | loss = 0.415550 | lr = 0.000727
Epoch 275 | loss = 0.433010 | lr = 0.000692
Epoch 300 | loss = 0.434203 | lr = 0.000658