
import matplotlib
if not hasattr(matplotlib.RcParams, "_get"):
matplotlib.RcParams._get = dict.get
Fall 2025 - Diffusion Guest Lecture#
Use the Live Code feature on this page using the icon on top.
Live Code feature works on this page.
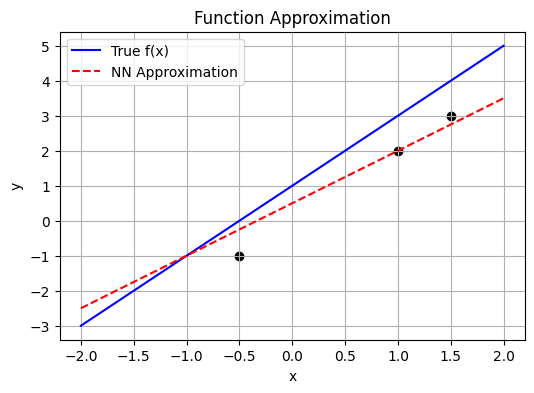
Function Approximators#
Neural networks are universal function approximators.
They learn to model an unknown function \(y = f(x)\) by training on pairs of \((x, y)\).
Given data points:
\((1, 2), (1.5, 3), (-0.5, -1)\), a network can learn \(f\) and predict \(y\) for new \(x\).
The goal is to find a function \(f\) such that:
In practice, \(f\) is parameterized by trainable weights.
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import interact, FloatSlider
# Toggle ON/OFF
interactive = True # ⇦ SET TO True or False
# True function to approximate
def true_f(x):
return 2 * x + 1
# Main plotting logic
def plot_approximation(weight=1.5, bias=0.5):
x = np.linspace(-2, 2, 100)
y_true = true_f(x)
y_pred = weight * x + bias
plt.figure(figsize=(6, 4))
plt.plot(x, y_true, label='True f(x)', color='blue')
plt.plot(x, y_pred, label='NN Approximation', linestyle='--', color='red')
plt.scatter([1, 1.5, -0.5], [2, 3, -1], color='black')
plt.title('Function Approximation')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid(True)
plt.show()
# Interactive or Static
if interactive:
interact(
plot_approximation,
weight=FloatSlider(value=1.5, min=-5, max=5, step=0.1),
bias=FloatSlider(value=0.5, min=-5, max=5, step=0.1)
)
else:
plot_approximation()
What is Data Distribution?#
Where does data come from?
Behind any dataset is a hidden data-generating process.
A random experiment (like flipping a coin) defines a random variable \(X\) whose outcomes follow a probability distribution \(p(x)\).
For discrete \(X\):
For continuous \(X\):
The PDF describes how likely different \(x\) values are.
Gaussian Distribution and Central Limit Theorem#
The Gaussian distribution, also called the Normal distribution, is a fundamental continuous probability distribution with a bell-shaped curve. Its probability density function (PDF) for a scalar random variable \(x\) is:
where:
\(\mu\) is the mean (the center of the distribution)
\(\sigma^2\) is the variance (the spread)
The Gaussian is symmetric about \(\mu\) and is fully described by its first two moments.
Central Limit Theorem (CLT):
The CLT states that the sum (or average) of a large number of independent and identically distributed (i.i.d.) random variables — regardless of their original distribution — will approximate a Gaussian distribution as the number of variables grows large. Formally:
The CLT explains why the Gaussian appears so frequently in nature and underpins many generative models and statistical inference techniques.
Why continuous Gaussian estimation is important?#
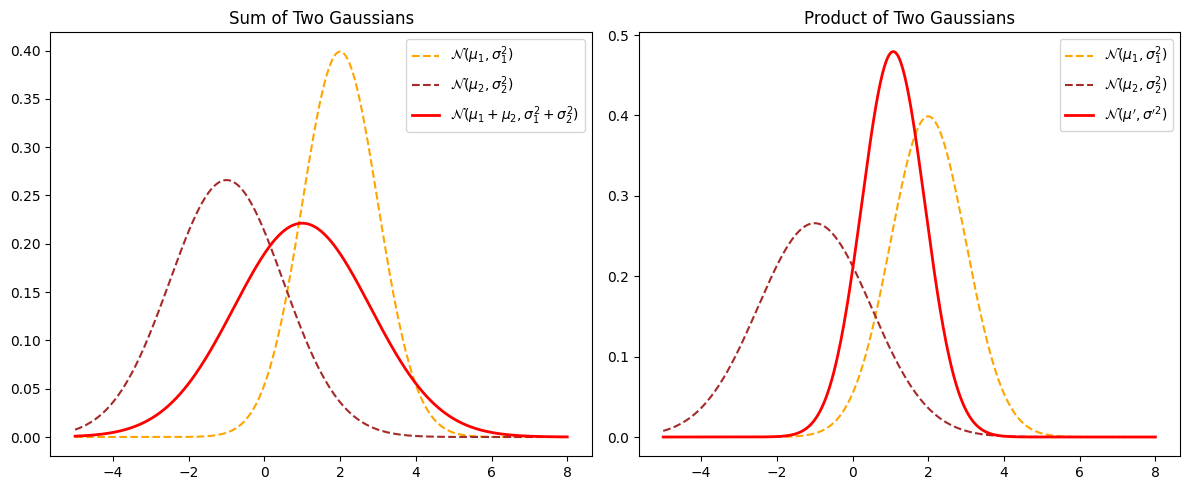
Sum and Product of Two Gaussians#
Sum of Two Gaussians#
If two random variables \(X\) and \(Y\) are independent and both normally distributed:
then their sum \(Z = X + Y\) is also Gaussian:
The mean adds and the variances add.
Product of Two Gaussians#
If we multiply the PDFs of two Gaussian distributions (often used in Bayesian updating), the result is proportional to another Gaussian:
The product is:
where:
So the product of two Gaussians is another Gaussian with updated mean and variance.
This property is fundamental for many Bayesian inference and Kalman filter algorithms.
from scipy.stats import norm
# Define parameters for two Gaussian distributions
mu1, sigma1 = 2, 1
mu2, sigma2 = -1, 1.5
# Define the range for plotting
x = np.linspace(-5, 8, 500)
# Compute the PDFs of the two Gaussians
pdf1 = norm.pdf(x, mu1, sigma1)
pdf2 = norm.pdf(x, mu2, sigma2)
# Sum of two independent Gaussians
mu_sum = mu1 + mu2
sigma_sum = np.sqrt(sigma1**2 + sigma2**2)
pdf_sum = norm.pdf(x, mu_sum, sigma_sum)
# Product of two Gaussians (up to a normalization constant)
sigma_prod = np.sqrt((sigma1**2 * sigma2**2) / (sigma1**2 + sigma2**2))
mu_prod = (mu1 * sigma2**2 + mu2 * sigma1**2) / (sigma1**2 + sigma2**2)
pdf_prod = norm.pdf(x, mu_prod, sigma_prod)
# Plot the Gaussians
plt.figure(figsize=(12, 5))
# Subplot for Sum of Gaussians
plt.subplot(1, 2, 1)
plt.plot(x, pdf1, label=r'$\mathcal{N}(\mu_1, \sigma_1^2)$', linestyle='dashed', color='orange')
plt.plot(x, pdf2, label=r'$\mathcal{N}(\mu_2, \sigma_2^2)$', linestyle='dashed', color='brown')
plt.plot(x, pdf_sum, label=r'$\mathcal{N}(\mu_1+\mu_2, \sigma_1^2+\sigma_2^2)$', linewidth=2, color='red')
plt.title('Sum of Two Gaussians')
plt.legend()
# Subplot for Product of Gaussians
plt.subplot(1, 2, 2)
plt.plot(x, pdf1, label=r'$\mathcal{N}(\mu_1, \sigma_1^2)$', linestyle='dashed', color='orange')
plt.plot(x, pdf2, label=r'$\mathcal{N}(\mu_2, \sigma_2^2)$', linestyle='dashed', color='brown')
plt.plot(x, pdf_prod, label=r'$\mathcal{N}(\mu^\prime, \sigma^{\prime 2})$', linewidth=2, color='red')
plt.title('Product of Two Gaussians')
plt.legend()
plt.tight_layout()
plt.show()
Expected Value: Definition and Practical Implementation#
The expected value (or mean) is a fundamental concept in probability and statistics that represents the long-run average outcome of a random variable.
For a continuous random variable X with probability density function p(x), the expected value is defined as:
For a discrete random variable:
When we only have a finite sample x_1, x_2, \(\ldots\), x_n, the expected value is approximated by the sample mean:
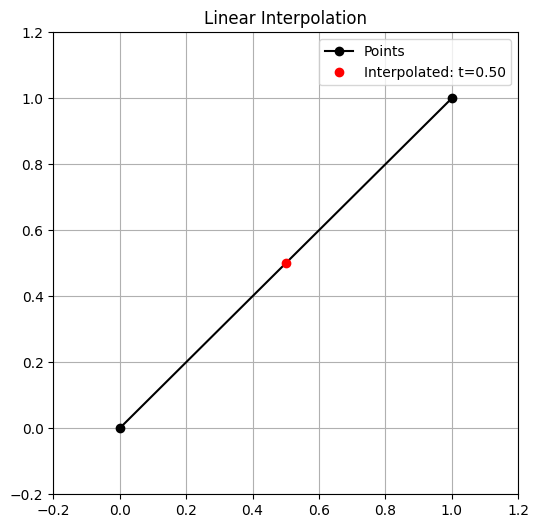
Interpolation as a Simple Generative Technique#
Interpolation is a basic yet powerful concept in generative modeling. When we interpolate, we create new data points by finding values between existing data points.
For example, given two data points x_1 and x_2, a simple linear interpolation is:
By varying \alpha between 0 and 1, we generate a smooth transition between the two original data points.
Why is this useful? • In low dimensions, it helps to fill gaps between sparse data. • In high-dimensional spaces (like images or embeddings), it is used to smoothly blend features. • Many generative models (e.g., VAEs) use interpolation in latent space to show how well the model captures smooth, meaningful variations in data.
Key idea:
Interpolation doesn’t truly create data from scratch, but it extends the dataset by exploiting the structure of known points. It’s a simple starting point for understanding how generative models synthesize new samples.
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import interact, FloatSlider
interactive = True
def plot_interpolation(t=0.5):
p0 = np.array([0, 0])
p1 = np.array([1, 1])
p = (1 - t) * p0 + t * p1
plt.figure(figsize=(6, 6))
plt.plot([p0[0], p1[0]], [p0[1], p1[1]], 'ko-', label='Points')
plt.plot(p[0], p[1], 'ro', label=f'Interpolated: t={t:.2f}')
plt.title("Linear Interpolation")
plt.xlim(-0.2, 1.2)
plt.ylim(-0.2, 1.2)
plt.grid(True)
plt.legend()
plt.show()
if interactive:
interact(
plot_interpolation,
t=FloatSlider(value=0.5, min=0.0, max=1.0, step=0.01)
)
else:
plot_interpolation()
Multivariate Gaussian Distribution#
A multivariate Gaussian distribution generalizes the normal distribution to multiple dimensions.
It models a vector of random variables \(\mathbf{X} \in \mathbb{R}^d\) that are jointly Gaussian.
Probability Density Function (PDF)#
The PDF of a \(d\)-dimensional multivariate Gaussian is:
where:
\(\mathbf{x} \in \mathbb{R}^d\) is the data vector,
\(\boldsymbol{\mu} \in \mathbb{R}^d\) is the mean vector,
\(\boldsymbol{\Sigma} \in \mathbb{R}^{d \times d}\) is the covariance matrix,
\(|\boldsymbol{\Sigma}|\) denotes the determinant of the covariance matrix,
\(\boldsymbol{\Sigma}^{-1}\) is its inverse.
Key Properties#
The mean vector \(\boldsymbol{\mu}\) defines the center of the distribution.
The covariance matrix \(\boldsymbol{\Sigma}\) encodes the variance of each dimension and the correlations between dimensions.
If variables are uncorrelated, \(\boldsymbol{\Sigma}\) is diagonal.
The multivariate Gaussian is fundamental for modeling high-dimensional continuous data and is widely used in generative modeling, probabilistic PCA, and Bayesian statistics.
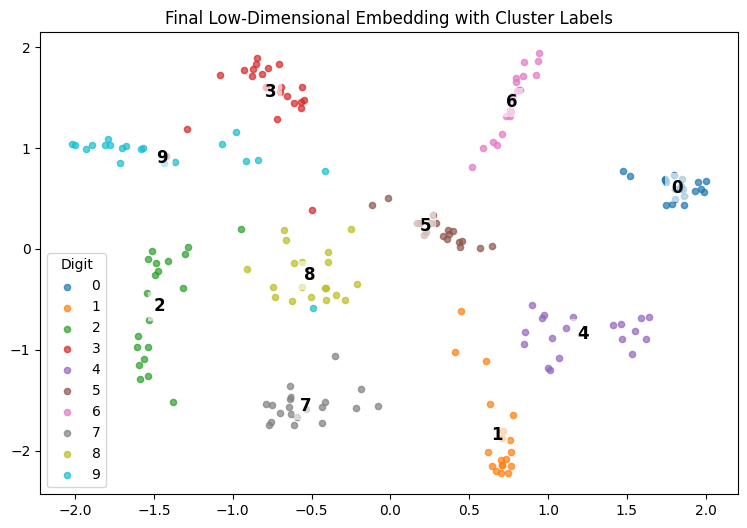
t-SNE: How It Works & How This Code Implements It#
What is t-SNE?
t-SNE (t-Distributed Stochastic Neighbor Embedding) is a nonlinear dimensionality reduction technique for visualizing high-dimensional data in 2D or 3D.
It preserves local structure: points close in high-dimensional space remain close in the low-dimensional map.
It works by converting pairwise distances into probability distributions:
In the high-dimensional space, similar points have higher conditional probability of being neighbors.
In the low-dimensional map, a similar distribution is constructed.
The algorithm minimizes the Kullback-Leibler (KL) divergence between these two distributions.
Key Steps in t-SNE
Compute pairwise distances
Uses squared Euclidean distance.
Convert distances to probabilities
High-dimensional distances → conditional probabilities via a Gaussian kernel.
Each point’s bandwidth (
sigma) is found via binary search so its perplexity matches the target value (controls effective neighborhood size).
Map to low dimensions
Points are initialized randomly in 2D.
Gradient descent adjusts positions to match the high- and low-dimensional probability distributions.
Symmetrize probabilities
Conditional probabilities are symmetrized to form joint probabilities.
Cost function
KL divergence measures how well the low-dimensional map matches the high-dimensional similarities.
How This Code Implements It
neg_squared_euc_dists — Computes negative squared Euclidean distances between points.
find_optimal_sigmas + binary_search — Finds the best sigma for each point to match the target perplexity.
p_joint — Computes the high-dimensional joint probability matrix.
q_tsne or q_joint — Computes the low-dimensional probability matrix (uses Student-t kernel for t-SNE).
estimate_sne — Runs gradient descent to adjust the embedding.
tsne_grad or symmetric_sne_grad — Computes the gradient of the cost function.
plot_embedding — Plots the final 2D embedding and labels each cluster at its mean.
Result:
This notebook loads digit data, computes a meaningful 2D embedding with t-SNE or SNE, and plots all classes clearly labeled at their cluster centers.
Encoder Decoder models for Data Generation#
Diffusion Models#
1. Motivation and Recap#
VAEs and GANs both aim to model complex data distributions.
VAEs: reconstruct well but can produce blurry samples due to simplified likelihood assumptions.
GANs: generate sharp samples but training can be unstable (mode collapse, convergence issues).
Diffusion Models offer a new paradigm:
They learn to generate data by gradually denoising a noisy input, reversing a diffusion (noise) process.
State-of-the-art in generative modeling, powering modern tools like Stable Diffusion and DALL·E 2.
2. Diffusion Models: Core Idea#
A diffusion model defines two processes:
Forward Diffusion Process (noising):
Gradually adds Gaussian noise to data \( \mathbf{x}_0 \) over \( T \) steps until it becomes nearly pure noise \( \mathbf{x}_T \).Reverse Diffusion Process (denoising):
Learns to reverse the noising step-by-step, generating realistic samples from noise.
3. Forward Diffusion Process#
We start with data sample \( \mathbf{x}_0 \sim q(\mathbf{x}_0) \).
Noise is added in small steps controlled by a variance schedule \( \{\beta_t\}_{t=1}^T \), where \( \beta_t \in (0,1) \).
3.1 Single Step#
3.2 Closed-Form Sampling#
We can directly sample \( \mathbf{x}_t \) at step \( t \) from \( \mathbf{x}_0 \):
where:
and noise injection is:
4. Reverse Diffusion Process#
We want to reverse the noising process:
The reverse conditionals are also Gaussian but unknown.
A neural network (usually a U-Net) is trained to predict the mean (and sometimes variance).
In practice, instead of directly predicting \( \mu \), we train the network to predict the noise \( \boldsymbol{\epsilon} \) added at each step.
5. Diffusion Model Training Objective#
Using variational inference, the training objective reduces to:
Here, \( \boldsymbol{\epsilon} \) is the true Gaussian noise,
\( \boldsymbol{\epsilon}_{\theta} \) is the predicted noise by the network.
Thus, the network learns to denoise step by step.
6. Comparison: VAEs vs Diffusion Models#
VAE Loss:
Diffusion Loss:
Diffusion models avoid blurry reconstructions by directly learning the data distribution via noise prediction.